Evidence96%Authoritative
FactConfirmedProduct·January 8, 2026
GLM-4.7 Available on Cerebras Inference Cloud at 1,000-1,700 Tokens/Second
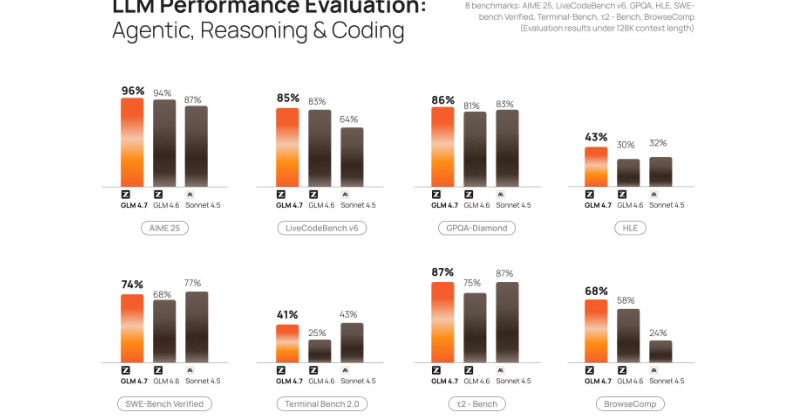
Z.ai's GLM-4.7, the top open-weight coding model surpassing DeepSeek-V3.2 on key benchmarks, launched on Cerebras Inference Cloud running at up to 1,700 tokens/second, which Cerebras states is 20x faster than closed-source competitors on GPUs.
Evidence Strength
Evidence96%Authoritative
Backed by official company doc
Single publisher source
Includes official or primary source
Insights
First tracked
November 18, 2025
Last updated
January 8, 2026
Sources
3 sources
Related Developments
Oklahoma City AI Datacenter Ribbon-Cutting with 44+ ExaflopsCerebras Delivers 3,000 Tokens/Second Inference for OpenAI's gpt-oss-120B Open-Weight ModelCS-3 vs. NVIDIA DGX B200 Blackwell Benchmarks PublishedJais 2 Arabic-Centric LLMs Trained and Deployed on Cerebras Wafer-Scale ClustersOpenAI Signs $10B+ Multiyear Compute Deal with Cerebras
Sources (3)
Source Timeline

- The world’s fastest GLM-4.6 – now available on CerebrasCerebras·Nov 18, 2025
Evidence Strength
Evidence96%Authoritative
Backed by official company doc
Single publisher source
Includes official or primary source
Insights
First tracked
November 18, 2025
Last updated
January 8, 2026
Sources
3 sources
Related Developments
Oklahoma City AI Datacenter Ribbon-Cutting with 44+ ExaflopsCerebras Delivers 3,000 Tokens/Second Inference for OpenAI's gpt-oss-120B Open-Weight ModelCS-3 vs. NVIDIA DGX B200 Blackwell Benchmarks PublishedJais 2 Arabic-Centric LLMs Trained and Deployed on Cerebras Wafer-Scale ClustersOpenAI Signs $10B+ Multiyear Compute Deal with Cerebras